Détourner les résultats des recherches Google par le duplicate content
Dan Petrovic à démontré comment il s’est approprié quelques pages de Google. Et ceci, avec des pages en duplicate content. Afin de positionner ses vulgaires copies dans les pages des résultats du moteur de recherche.
Par exemple, il a pu tromper Google. Afin qu’il pense afficher un page de « Marketbizz » alors qu’il affiche une page de dejanseo.com.au, et non pas marketbizz.nl.
Mais alors comment à t’il fait avec du contenu dupliqué ? Il a simplement copier le code source de la page complète. Ainsi, il a mis un copie sous une nouvelle URL de son site dejanseo. Il l’a lier et ajouté à ses médias sociaux tel que Google+1 et la suite est arrivé quelques jours après.
Voici une photo de la page de recherche Google utilisant des renseignements, commandes et cherchant aussi le titre de celle-ci.

Il fit la même manipulation sur trois autres noms de domaines avec des résultats plus ou moins concluant.
Nous avons écrit à Google la semaine dernière afin d’avoir un commentaire, mais nous n’avons toujours pas eu de réponse de leur part.
Dans certains cas, utiliser une «URL-canonique » par le tag rel=’canonical’ peut éviter de sa faire voler la paternité d’une page dans les résultats, mais pas toujours. Il semble aussi y avoir un avantage à utiliser l’authorship.
Dan Petrovic a même réussi à détourner le premier résultat pour le nom « Rand Fishkin » (avec sa permission), comme on peut le voir sur l’image suivante :
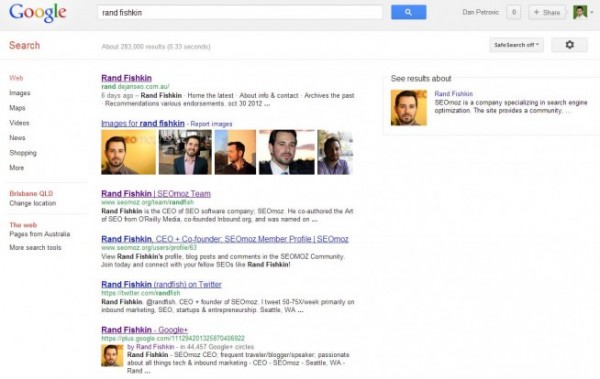
Le filtre du contenu dupliqué de Google pense que la nouvelle URL est plus importante et remplace ainsi la page originale par celle-ci. C’est pourquoi le competitive link trick à fonctionné si bien.
Post-scriptum : Google à modifié le merge des urls à partir de Googel Webmasters tools et agi dorénavant contre ces tentatives avec une notification envoyée à l’administrateur web pour : «contenue copié».
Source [http://searchengineland.com/hijacking-google-search-results-without-hacking-139655]
![Cbcf4390b9134261a05381ab86116e8a[1]](https://www.web-biz.fr/wp-content/uploads/2021/05/cbcf4390b9134261a05381ab86116e8a1.jpeg.webp)



0 Commentaires